SPSS's data-handling facilities make it useful for studying ego-centered networks. Such networks are useful for studying a variety of subjects, such as social support, personal community, and an organization's relationships. We show how analyses of ego-centered networks are best done by starting with two data sets: (1) focal individuals and their ego-centered networks; (2) network members and their ties with focal individuals. We show how to link these two data sets to (a) calculate summary information about each ego-centered network; (b) combine focal individual, tie and network data.
Note: This article has been developed from "How to Use SAS to Study Ego-Centered Net works" (Wellman 1992a), itself a thoroughly revised version of Wellman and Baker (1985).
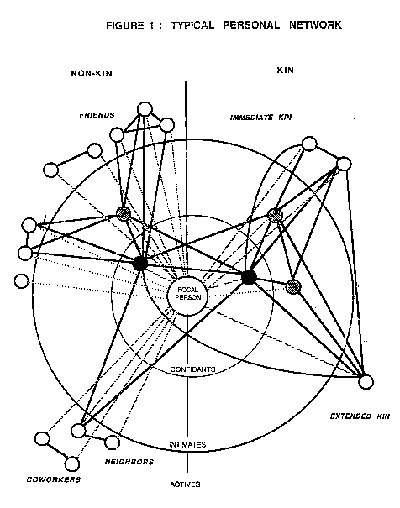
Many social network analysts study ego-centered networks, networks defined "Ptolemaically" from the standpoints of focal individuals (Figure 1). Ego-centered (or personal) network analyses are common in the study of community and social support (e.g., Wellman 1999), and they can be used for studying other matters such as corporate relations. Most ego-centered analyses have studied only the direct ties that focal individuals have with the members of their networks. A few analyses have studied the links that network members have among themselves, and a very few have studied a focal individual's indirect ties, such as their ties to the friends of their friends.
This article presents some ways of using SPSS software to analyze ego-centered networks. SPSS is one of the most widely-used software packages in the social sciences. It has been crucial in facilitating do-it-yourself research using individuals as discrete units of analysis. (Wellman 1998). However, quantitative studies of ego-centered network data are more complicated than survey research that use individuals as units of analysis. Network analysts must keep track of several different types of information (Campbell and Lee 1991):
(back)
We deal here only with the basic and most common case: studying first-order, direct ties between focal individuals and their network members. In such analyses, a basic set of problems is how to store and link individual, tie and network data in useful and efficient ways. This article describes some ways of using SPSS to handle these matters.
The basic procedure is to....
Tiewise: In tiewise data sets, the characteristics of alters include both their personal characteristics (such as age and gender) and their tie characteristics (such as a sibling relationship).
By definition, a focal individual and a network member have exactly one tie, although a single tie often contains multiple role relationships. Even though the tie is between the focal individual and the network member, for computational purposes you can treat network members as "possessing" the characteristics of their ties with focal individuals. This makes it possible to store both network member and tie variables in one data set (arbitrarily called TIE in this article).
Netwise: By definition, focal individuals are at the centers of their own ego-centered networks (Figure 1). Thus focal individuals not only have personal characteristics such as gender and ethnicity, they have networks with different densities, numbers of clusters, etc. Hence, analysts can store information about focal individuals and their networks in the same records of a netwise data set (arbitrarily called NET in this article). However, it is often more useful to use the procedures described in this article to compute data about the composition of networks.
Data Entry: One special condition for data entry must be met. The otherwise separate tiewise and netwise data sets must each contain the same variable (arbitrarily called NETID in this article) that uniquely identifies each focal individual.
In the tiewise data set, the NETID variable uniquely identifies the ego-centered network to which each network member belongs. If several network members belong to the same network, each of the network members will have the same NETID number. In the tiewise data set, the NETID variable is used to produce summary information about each network and to join this summary information with the information about focal individuals that is in the netwise data set.
In the netwise data set, the NETID variable uniquely identifies the focal individual and his/her network.
(Note on importing data.)
Each tie in the TIE data set should also have a unique TIEID. This is necessary for tie-wise analysis. A useful trick is to create the TIEID variable from a combination of TIENUM and NETID. TIENUM uniquely identifies the members of each network, numbering them within each network from "1,2,3, ... N". By combining the NETID and the TIENUM variables you get one new unique TIEID number for each tie in the entire data set (e.g., "14115") where the first three digits (e.g., "141") represent the NETID of the ego and the last two digits (e.g., "15") represent the TIENUM. Thus TIEID "14115" represents tie #15 of ego #141. At times this can give you useful information as when you want to identify the ties in all the networks that have very high frequencies of contact with focal individuals.
(NETID * 100) + TIENUM =TIEID
The SPSS AGGREGATE procedure computes summary statistics such as means across groups of cases and produces a new SPSS system file containing one case for each group. The variables of this aggregated file are the summary measures. This feature allows analysts to produce network compositional data such as the mean frequency of contact for each network, the percentage of network members who provide emotional support, and the number of network members who provide emotional support.
(Note: Use separate working copies of the original data sets while doing data transformations so that you can always go back to your original variables in case you make a mistake or change your mind.
To use the AGGREGATE procedure, three sets of information must be specified:
This approach allows analysts to produce summary statistics for each ego-centered network. For example, instead of computing the mean frequency of contact for the entire sample of ties, analysts can compute separate means for each focal individual's network.
Information about 343 network members is stored in the TIE file (the example is from Wellman 1992b). The following SPSS procedure creates the new outfile data set TIESUM, containing summary information about the 29 networks to which these 343 network members "belong".
Note: Do not use the numbers in the above example ("1.", etc.) in your SPSS statement. They are merely guides to the explanation that follows this note.
1. GET FILE="C:\TIE.SAV".(Note: Other SPSS subcommands, such as /MISSING or /PRESORTED, are not discussed in this article.)
AGGREGATE2. /OUTFILE="C:\TIESUM.SAV"3. /BREAK=netid
4. /mftf pemaid mctage = MEAN (ftf emaid ctage)
/sftf semaid = SUM (ftf emaid).
5. EXECUTE.
6. GET FILE="C:\TIESUM.SAV".
VARIABLE LABELSmftf "mean ftf contact"pemaid "pct of emotional aid"
etc.
1. The "GET FILE=" command indicates your input file, in this example: "C:\TIE.SAV". Always specify the file with a complete path (drive and directory) and enclose it in single or double quotation marks. (back)
2. In the second step you define an output file where aggregated data will be stored. The /OUTFILE statement directs SPSS to create and store a new data set: "TIESUM.SAV". This data set will contain the summary statistics requested in the AGGREGATE procedure for each value of NETID (that is, each network). (back)
3. The /BREAK subcommand specifies that statistics are to be computed separately for each value of the variable NETID. This is the crucial step. Since each of the 343 network members has one of 29 NETID values, summary statistics for each of the 29 networks will be computed for the variables listed in the fourth step of the procedure (see the next paragraph). Thus the /BREAK statement transforms tie information into by-network summaries: one summary for each of the 29 ego-centered networks. (back) (Note on sorting your data file.)
4. In this fourth step, there are three tie-level variables in the tie data set to be aggregated: the frequency of a network member's contact with ego, whether a network member provides emotional aid (defined as 0=no support, 1=provides support), and a network member's age.
(Note: This "0/1" coding is a handy tool for using means to calculate the proportion of network members (or ties) who posses a given characteristic such as "provides emotional aid".)
Each new variable in the aggregated file is created by applying an aggregate function to a variable in the active input file (here the active file is called "TIE.SAV"). SPSS requires that these new variables be entered in the same order as their tiewise counterparts in the statement that follow the "=" sign. If PEMAID is the second new variable to be defined, then EMAID must be the second source variable mentioned after the equal sign ("="). If you scramble the order or omit a variable name, your output will be horribly wrong. Even, it can be unobtrusively wrong.
The new variables in the TIESUM data set are created by the MEAN and SUM operations. In the example, these are the mean frequency of contact of an ego with all network members, the percentage of an ego's network members who provide support, the mean age of the members of an ego's network, the total frequency of contact an ego has with network members, and the number of an ego's network members who provide support. Thus the new variable MFTF is computed by "=MEAN (ftf)", referring to the variable defined in the tiewise data set. Similarly, totals of variables can be computed by the SUM operation: "[newvarlist] = SUM [oldvarlist]". Thus SFTF equals the total amount of contact that all members of an ego-centered network have with its focal individual.
In this example, we adopt the convention of keeping the variable names the same in both the TIE and TIESUM data set, except that they are preceded by either a "M" (mean) or "S" (sum or total). We also use a "P" prefix for mean variables that have been calculated from 0/1 binary codes in the tiewise data set. (Note on aggregating percentages). The mean in such cases is also the proportion of ties in a network that have a particular characteristic, such as the proportion of ties that provide emotional aid. Although you can choose any names you want for such variables, conventions such as these help to keep track of things by associating the original tiewise variables with the newly-created netwise summary variables.
These new variables are netwise summaries of the tiewise information for each focal individual. Thus, MFTF equals the mean face-to-face contact between a focal individual and the members of his/her network. Since emotional support was coded 0/1 in TIE, the proportion of ties in each network that provide it are computed by the MEAN operation and exported as the PEMAID variable in the new TIESUM file.
In another example, a new SFTF variable is created by the SUM operation of the initial FTF variable, representing the total amount of face-to-face contact between each focal individual and all members of his/her network.
AGGREGATE can also output other summary statistics. For example, you can calculate the standard deviation "SD (variable list)" to measure the SES and age heterogeneity of ego-centered networks. (back)
5. Some SPSS procedures use the EXECUTE command to force data reading. (back)
6. As the AGGREGATE procedure by default creates new variables without any labels, we recommend immediately using the usual SPSS labeling procedures to name the aggregated variables, as is done here.
Note that in order to operate with the new file "TIESUM.SAV", you have to make it the active file:
GET FILE="C:\TIESUM.SAV".(back)
Use AGGREGATE to calculate network size. One method is to create a new variable defined by the "N" function that counts the number of cases in a break group.
AGGREGATE/OUTFILE="C:\TIESUM.SAV"/BREAK=netid
/netsize=N.
This new variable, netsize represents the weighted numbers of all entries for each break group, that is in our example, for each network. Similarly, the function "NU" computes the unweighted numbers.
Another method for calculating network size is to copy NETID to a new variable (arbitrarily called TEMP here) so that you can recode it without destroying it. (Use NETID for this because it should never have missing values.) Recode TEMP so that all non-missing values ="1". If you include TEMP in your AGGREGATE procedure, the SUM of TEMP will be the size of each network:
AGGREGATE/OUTFILE="C:\TIESUM.SAV"/BREAK=netid
/netsize = SUM (temp).
Using the same approach with more recoding will provide more specialized counts, such as the number of kin.
The approach described above has provided information about the composition of each ego-centered network. You can now use the "TIESUM.SAV" file directly to compare networks. In this example we use CORRELATIONS to correlate the mean frequency and total amount of face-to-face contact in each network with the proportion of network members who provide emotional aid.
GET FILE = "C:\TIESUM.SAV".CORRELATIONS
/VARIABLES=mftf sftf pemaid.
Linking Tie Information with Information about Focal Individuals and Network Structure
With a "MATCH FILES" statement, you can combine the newly-created TIESUM data set with the NET data set that contains information about focal individuals and the structure of their networks. SPSS does this by "match merging" the TIESUM and NET data sets. It combines records that have the same value for the network identification variable (NETID). That is why analysts must make sure during data entry that both TIESUM and NET contain matching NETID values. NETID is in the original NET data set. It also is carried over automatically from TIE to TIESUM when it is used in the /BREAK subcommand of the AGGREGATE procedure.
Sort both files you want to merge by the break variable specified in the BY command. If you run the AGGREGATE procedure immediately before the MATCH FILES procedure, then AGGREGATE will sort the cases itself. In any case, we recommend sorting both input files by the break variable (e.g., NETID, in ascending order) before you run a MATCH FILE procedure. If you save your data sorted "by netid," you will not have to sort it again.
GET FILE="C:\NET.SAV".SORT CASES BY netid (A).
SAVE OUTFILE= "C:\NET.SAV" /COMPRESSED.
GET FILE="C:\TIESUM.SAV".
SORT CASES BY netid (A).
MATCH FILES
/TABLE=*SAVE OUTFILE= "C:\NETALL.SAV" /COMPRESSED./FILE="C:\NET.SAV"
/BY netid
/MAP.
The preceding commands create a new netwise data set named "NETALL.SAV" formed by the merger of the TIESUM and NET data sets. The star symbol in "/TABLE=*" indicates that the table of the new outfile "NETALL.SAV" is defined by your active system file (the one you recalled last), in our example "TIESUM.SAV". SPSS allows you to apply the /MAP subcommand, which displays a list of variables in the new data set, their order, the file from which they came, and their original names. The /MAP subcommand follows the /BY subcommand.
SPSS also allows you to apply the /KEEP command "/KEEP=[varlist]" to keep only those variables that you need for the present operation in the active file. This saves computer time. Or, if more convenient, you can use the /DROP command to exclude unneeded variables.
(...)MATCH FILES
/TABLE=*SAVE OUTFILE = "C:\NETALL.SAV" /COMPRESSED./FILE="C:\NET.SAV"
/RENAME= (oldvar=newvar)
/BY NETID
/DROP=mftf
/MAP.
Now you are in a position to examine such matters as the relationship between focal individuals' gender (originally located in NET) and the percentage of emotional aid in their networks (created in TIESUM):
GET FILE="C:\NETALL.SAV".CORRELATIONS
/VARIABLES=gender pemaid.
You can also use information about focal individuals to study subsamples of networks. For example, the following will do correlations only for the networks of men:
GET FILE="C:\NETALL.SAV".TEMPORARY.
SELECT IF (gender EQ 1).
CORRELATIONS
/VARIABLES=mftf sftf pemaid.
The TEMPORARY command ensures that the SELECT IF statement will only be applied to the operation that follows it. If you want to export your selected data into a separate file of male cases only ("MEN.SAV"), then you do not need to apply the TEMPORARY command:
GET FILE="C:\NET.SAV". SORT CASES BY netid (A).SAVE OUTFILE= "C:\NET.SAV" /COMPRESSED.
GET FILE="C:\TIESUM.SAV".
SORT CASES BY netid (A).
MATCH FILES
/TABLE=*SELECT IF (gender EQ 1)./FILE="C:\NET.SAV"
/BY netid
/MAP.
SAVE OUTFILE= "C:\MEN.SAV" /COMPRESSED.
Another possibility is to apply the SPLIT FILE procedure. For example, to get separate sets of correlations for men and women, first sort the cases BY GENDER:
GET FILE="C:\NETALL.SAV".SORT CASES BY gender.
SPLIT FILE BY gender.
CORRELATIONS
/VARIABLES=mftf sftf pemaid.
If you apply the SPLIT FILE command, either remember to turn it off after the procedure ("SPLIT FILE off") or use the TEMPORARY command for every SPLIT FILE procedure.
Analysts may also want to retain the tiewise organization of the TIE data set, but supplement it with information about focal individuals (NET data) and network structure (NETALL data). For example, Wellman (1992b) needed to know the gender of focal individuals and of network members in order to compare ties between men, between women, and between men and women. The sample size in this example is 343 ties and not the 29 networks produced through the AGGREGATE and MATCH FILES examples described above.
In this example, the NETALL data set is merged with the tiewise TIE data set to form a new data set arbitrarily called TIEFOCAL. As in the preceding example, "MATCH FILES /BY netid" associates the appropriate records in TIE and NETALL data sets (which itself includes the NET data). (Here too, you have to take care that both input files are pre-sorted by the same variable.)
In this situation, if the focal individual has 10 ties, the information from NETALL will be copied 10 times and merged with each network member's record. The merged TIEFOCAL data set will have 343 records, like TIE, but it will be larger because the focal individual's information and the summary information (both stored in NETALL) is repeated for each member of his/her network.
GET FILE="C:\NETALL.SAV".SORT CASES BY netid (A).
SAVE OUTFILE= "C:\NETALL.SAV" /COMPRESSED.
GET FILE="C:\TIE.SAV".
SORT CASES BY netid (A).
SAVE OUTFILE= "C:\TIE.SAV" /COMPRESSED.
GET FILE="C:\NETALL.SAV".
SORT CASES BY netid (A).
MATCH FILES /TABLE=*
/FILE="C:\TIE.SAV"SAVE OUTFILE="C:\TIEFOCAL.SAV" /COMPRESSED./BY netid.
1. This approach will work only if the original TIE data set is used and not the summary TIESUM data set that AGGREGATE creates.
2. This will work only if similar variables in the original TIE and NETALL data sets have different names. Otherwise, disaster can strike as when a TIE variable named SEX in the TIE data set (network member's sex) is merged with a NET variable named SEX in the NETALL data set (focal individual's sex). We suggest using consistent, unique prefixes (e.g., TSEX and FSEX) in the original TIE and NET data sets. If similar variables in both data sets have the same name, rename them applying the SPSS subcommand: "/RENAME=(oldvar=newvar)" following the /FILE subcommand when you merge your data sets. For example, if both data sets contain the variable SEX, rename the variable in the TIE.SAV file using the following commands:
GET FILE="C:\NET.SAV"SORT CASES BY netid (A) .
MATCH FILES
/TABLE=*/FILE="C:\TIE.SAV"
/RENAME=(sex=tsex)
/BY NETID.
3. You can reduce the size of the merged TIEFOCAL data set by using a /KEEP or /DROP statement to limit the number of variables that will be merged. This is especially useful in reducing the size of the NETALL data set because its variables will be repeated for many (TIE) records when TIEFOCAL is created.
1. It is easy to link summary data to information about the characteristics of focal individuals. Moreover, you need not make linkage decisions ahead of time. At any time, analysts can choose to combine different characteristics of focal individuals and networks. It is also easy to focus on the ties or networks of specific types of focal individuals (such as men).
2. To identify focal individuals, ties, and networks that have high or low values on a specific variable, use the "SELECT IF (variable=value)" command for analyses. For example, Wellman and Wortley (1990) used this option to identify those focal individuals whose networks provide very high or low levels of emotional support. Precede each SELECT IF, SPLIT FILE or DO IF command by the TEMPORARY command, unless you want to export data in a separate file.
Alternatively, you can split specific files while using the AGGREGATE procedure. To do it this way, do not use the SPLIT FILE command, but define the variable(s) to be split (e.g., "gender") as the break variable(s) ahead of any other variable(s). AGGREGATE will produce one file, but with separate output for each value of the break variable.
3. Keeping two separate data sets is more efficient than combining tie and network data into one set because it avoids the repetition of individual, tie, and network information. Moreover, separate tie and network data sets permit doing more efficient computer runs when only one data set is needed.
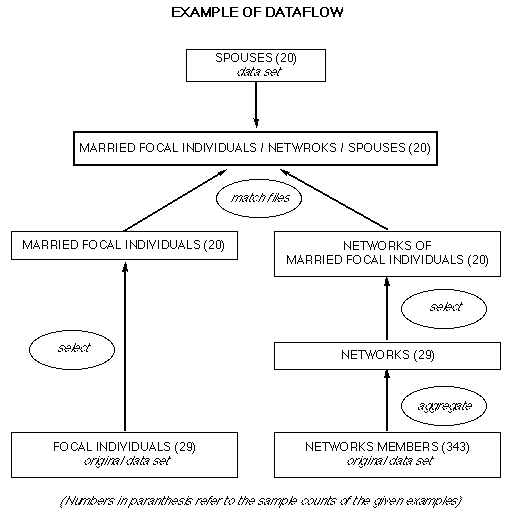
4. The general approach described here can be extended. For example, Wellman and Wellman (1992) linked TIE and NET data with a third data set containing information about marital relationships. They used SAS software with multiple UNIVARIATE and MERGE procedures to accomplish this (Figure 2). Applying the AGGREGATE and MATCH FILES procedures for SPSS described in this paper would also do this.
FIGURE 2
5. The confirmatory statistics produced by SPSS (such as correlation coefficients and their associated significance levels) assume that each record is an independent unit of analysis (Wellman 1998). This may not be the case in ego-centered network analysis. To be sure, focal individuals and networks often are independent units. Hence analyses using NET and TIESUM rarely have this problem. However, the ties of a focal individual are inherently not independent from each other; they are clustered in the focal individual's network. Therefore, a sample of many focal individuals' ties -- as stored in TIE or TIEFOCAL -- is not a fully independent sample even if the focal individuals were sampled independently. The variance in such data sets should be lower than in a fully independent sample. It may be possible to treat a tiewise data set as a cluster sample. A relatively new method, multilevel analysis (often done as hierarchical linear modeling) promises to help deal with this problem (Bryk and Raudenbush 1992; Snijders 1994; Frank and Wellman 1998; Thomése and van Tilburg 1998; Van Diujn, van Busschbach and Snijders 1998).
6. It is difficult to use SPSS or SAS to calculate measures of whole network structure without writing specialized matrix routines. Use UCINET (Borgatti, Everett and Freeman 1999) or MULTINET (Richards 1994) instead. Analysts then can add structural measures calculated with these programs to the NET data set for further analyses using SPSS or SAS.
1) Procedures and syntax presented in this article have been tested for SPSS for Windows versions 6.1.2., 7.0, 7.5 and 8.0, as well as for "SPSS 6.1 for Power Macintosh". There may be slightly different notations for other SPSS versions, including versions for mainframes. If your ego and alter data are initially stored in the same data set, you will first have to separate them into two data sets, as described by Wolf (1993). It is better to enter the data at the start in separate tiewise and netwise data sets. (back)
3) Unlike the SAS UNIVARIATE procedure, you do not have to sort your input file, because SPSS does this by routine. However, storing the data permanently in one specific order can save time and avoid problems. In our example, we would normally store by the ascending values of the NETID variable so that focal individual 1 comes first, focal individual 2 comes second, and focal individual 343 comes last. The commands are
SORT CASES BY netid .
SAVE OUTFILE="filename" /COMPRESSED" .
As long as you do not save your file again, it will remain sorted "by netid" every time you recall it with the GET FILE command. (back)
4) SPSS also allows you to compute percentages for non-binary variables, using the following functions:
"PGT (varlist, value)" for percentages "greater than" the specified value,
"PIN (varlist, value1, value2)" for percentages of cases "between value1 and value2", or ...
PLT (for cases "less than ...") or ...
POUT (for cases "not between value1 and value2").
For example, the statement "/pgtctage = PGT(ctage 40)" computes the percentage of all cases where the variable "ctage" has a value greater than "40", i.e., the percentage of network members in each network who are older than 40 years. (back)
Borgatti, Stephen, Martin Everett and Linton Freeman. 1999. UCINet 5 for Windows. Natick, MA: Natick Analytic Technologies.
Bryk, Anthony and Stephen Raudenbush. 1992. Hierarchical Linear Models: Applications and Data Analysis Methods. Newbury Park: Sage.
Campbell, Karen and Barrett Lee. 1991. "Name Generators in Surveys of Personal Networks." Social Networks 13 (Sept.): 203-22.
Frank, Kenneth and Barry Wellman. 1998. "Network Capital in a Multi-Level
World: How Individuals, Ties and Networks Provide Social Support in
Contemporary Communities." Presented to the Conference on Social Networks
and Social Capital, Durham, NC, October.
Snijders, Tom. 1994. "Multilevel Methods for Analyzing Relational Data." Presented to the International Conference on Personal Relationships. Groningen, Neth., July.
SPSS. User's Guide . Many editions. Chicago: SPSS.
Richards, William. 1994. Multinet. Burnaby, BC, Canada: Department of Communication Studies, Simon Fraser University.
Thomése, Fleur and Theo van Tilburg. 1998. "The Importance of Being Close Together: Contextual Effects of Neighbouring Networks on the Exchange of Instrumental Support Between Older Adults and Their Proximate Network Members in the Netherlands." Working Paper. Department of Sociology, Free University of Amsterdam, April.
Van Diujn, Martijtje, Jooske van Busschbach and Tom Snijders. 1998. "Multilevel Analysis of Personal Networks as Dependent Variables." Working Paper. Interuniversity Center for Sociological Theory and Methodology, University of Groningen, Netherlands. May.
Wellman, Barry. 1988. "The Community Question Re-evaluated." Pp. 81-107 in Power, Community and the City, edited by Michael Peter Smith. New Brunswick, NJ: Transaction.
Wellman, Barry. 1992a: How to use SAS to Study Egocentric Networks.
Cultural Anthropology Methods Newsletter, June 1992: 6-12.
Wellman, Barry. 1992b. "Men in Networks: Private Communities, Domestic Friendships." Pp. 74-114 in Men's Friendships, edited by Peter Nardi. Newbury Park, CA: Sage.
Wellman, Barry. 1998. "Doing It Ourselves: The SPSS Manual as Sociology's Most Influential Recent Book." Pp. 71-78 in Required Reading: Sociology's Most Influential Books, edited by Dan Clawson. Amherst: University of Massachusetts Press.
Wellman, Barry. 1999. Networks in the Global Village. Boulder, CO: Westview.
Wellman, Barry and Susan Gonzalez Baker. 1985. "Using SAS Software to Link Network, Tie and Individual Data." Connections 8 (2-3): 176-87.
Wellman, Barry, Ove Frank, Vicente Espinoza, Staffan Lundquist and Craig Wilson. 1991. "Integrating Individual, Relational and Structural Analysis." Social Networks 13 (Sept.): 223-50.
Wellman, Beverly and Barry Wellman. 1992. "Domestic Affairs and Network Relations." Journal of Social and Personal Relationships 9 (August): 385-409.
Wolf, Christof. 1993. "Egozentrierte Netzwerke: Datenorganisation und Datenanalyse." ZA-Informationen 32: 72-94.
--> Hauptseite --> page d'introduction --> main page
www.socio5.ch © produced: 12.7.99 - updated: 8.2.2004 © Christoph Müller Kontakt / Contact / Disclaimer